Shazam for medicine box: ML on mobile when you don't have a barcode

Meditect is a company that provides medical software for pharmacists and patients in West Africa. We originally developed a traceability solution, and lately a business management software for pharmacy.
One of the most basic uses is to quickly identify a product. Whether for a pharmacy point of sale or for a patient to obtain medical information.
Most of the time, a barcode does its job pretty well. But the West African market has the particularity that roughly 1/3 of products don't have any. Pharmacists work around the problem by sticking barcode labels supplied by their wholesalers. But patients or customs agencies still have to deal with it, especially for counterfeit products which by definition are mostly sold outside of pharmacies. And if you can always do a text search, it remains slow and error-prone.
Value proposition
We hypothesized that Machine Learning could keep a simple promise: identify a product by holding a medicine box in front of a smartphone camera. Since you can already recognize a plant or a bottle of wine, the promise seemed reachable to us.
Our context has several particularities:
- Product differences could be subtle. For instance, it can only be a different active ingredient dosage (500 mg vs 1000 mg)
- Products usually have both an English and French side
- Dozens of new products are released to the market every month
- There is simply no existing dataset for medicines, in the world as in West African
- Mobile networks are slow and unreliable. Better bet on on-device inferences (MLKit is great) than waiting for a server-side remote processing
- Devices are mostly entry-level models with low-end cameras, sometimes even without autofocus
Facing the unknown
The basic approach for identification is to use multi-class classification. You end up with a probabilities distribution across all your classes used during training. But what if you have now a new product, and need to add its class to your classifier? You have no choice but to retrain your entire model.
An alternative is to use fingerprints. The idea is to generate a vector from an image, being the most specific of a product regardless of noise (orientation, background, lighting, etc.). To identify a product in an image, we compare its vector to a list of reference vectors for all existing products. Such comparison is performed using cosine distance: the closest value to 1 (same vector) corresponds to the identified product https://medium.com/@sorenlind/nearest-neighbors-with-keras-and-coreml-755e76fedf36. And reference vectors are previously calculated with images from a basic desktop scanner, for every product sold in the West African market.
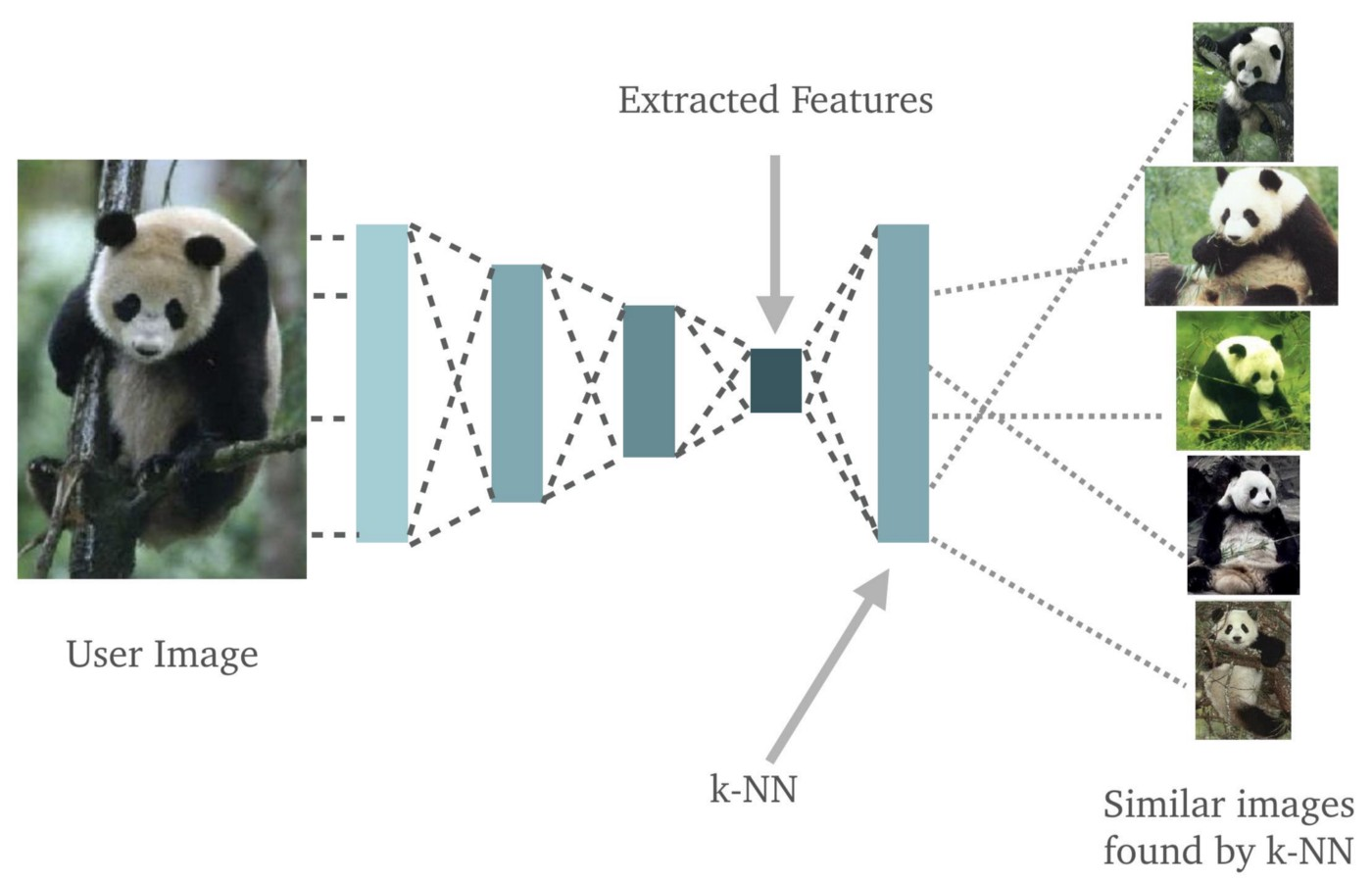
Such a classifier has the great advantage of being easily extendable: for any new product, you only need to generate a new fingerprint from a reference image and add it to the existing list.
Small is beautiful
To get a good fingerprint, the idea is to generalize what you want to identify. And neural networks are great for that.
Convolutional Neural Network (CNN) is trendy in image recognition, and more generally in domains where the convolution takes advantage of the local context (text or speech recognition for instance). They however have a lot of parameters, and are resource intensive to train, since your dataset size depends roughly on your model complexity. A classic trick is to use transfer learning by scrapping the last classification layer of a free model (Inception, VGG, ResNet, etc) already trained on a lot of everyday objects and animals. It's ok to detect pangolin based on cat and dog training, but not so much for medicine boxes, with specific topology (surfaces, edges, and corners), texts of different sizes, background colors, brand logos, etc.
Our solution, based on https://medium.com/@sorenlind/a-deep-convolutional-denoising-autoencoder-for-image-classification-26c777d3b88e, was to use a denoising autoencoder. Autoencoders consists of an encoder and a decoder, linked by a latent vector. After training the model to generate the reference noise-free image of a product from every noisy image, you could throw away the decoder and use the latent vector to generate fingerprints: it embeds what a medicine box is, independently of acquisition noises.
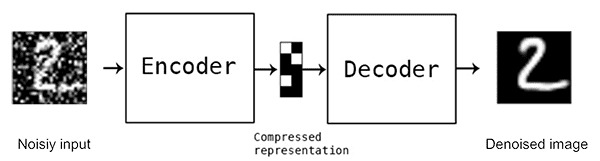
The real trick was to optimize this latent vector size. Too small and you're not specific enough because you lose information. Too big and you embed noise or sparsity and fall into the curse of dimensionality.
Pimp your dataset
Still, building a dataset from scratch is time and resource-consuming. Most of the hours are spent on various and tedious data transfers, renaming, selection, and cleaning.
Generalization is mostly about varying your noise. In our case, it's mostly image background and box orientation, and a bit of luminosity, reflections, and hand obstruction. Image augmentation (gaussian noise, rotation, symmetry, etc) can help you a bit, but you can't ignore reality and the need for real-life backgrounds and orientations.
We used 2 tricks to speed up the process. First, we took videos instead of still images, while randomly rotating each box in front of the camera. Capture is greatly accelerated, and image sampling from the video could be finely tuned afterward.
Secondly, we filmed an additional video with a green screen background. A relatively simple post-processing then allowed us to embed as many backgrounds as wanted.
Trust in me
So far, we've built a model which, for each image of a video stream, generates a list of distances to every product, and therefore the best candidate. We have now to set a threshold, and decide if the product is detected or not.
There is always a tradeoff in classification between specificity and sensitivity. Too high a threshold and we will see products where there are none (false positive). Too low a threshold and we will miss detection (false negative).
There is no right or wrong choice. It depends on the use cases and your user's acceptance of false positives and negatives.
In practice, the classic approach is to use ROC curves and Youden's index to find an optimal threshold value.
The best of both worlds
Ultimately, the goal is to help your users. And most of the time you want to bundle trust in your answer, not bother them with informed consent.
Our case however is typical of a lot of Machine learning applications: good enough to show some magic, be not enough to be reliable.
To greatly improve our performance, we built an additional model to run parallel to our denoising autoencoder classifier. Its only role was to detect medical boxes and act as a first-stage filter before product classification.
This time, a CNN with transfer learning did the job perfectly. Because detecting medical boxes mostly means discerning them from daily objects and animals.
If better is possible, good is not enough
Together, the 2 models offer an accuracy of around 95%. An honorable performance in ML, especially from a small dataset.
In the end, we unfold a market reality. First, 5% of false results is still unacceptable for a medicine. Misidentifying a product to a patient or a custom agency could result in a serious health hazard. Secondly, pharmacists systematically work around the problem by using 100% accurate barcode stickers provided by their wholesalers.
Ultimately we had to kill the project and focus on pharmacy management software. That being said we learned a lot and proved to ourselves that developing a production-ready solution with limited resources and existing tools was possible.